cursor.com
AI Coding Tools Weekly: Composer 2.5 on Kimi K2.5, Copilot's LTS model, Google goes closed-source
This week's digest covers 12 tools and 27 confirmed events: Cursor's Composer 2.5 (built on open-source Kimi K2.5, ~10× cheaper than Opus 4.7 at comparable benchmarks) leads alongside a Gartner MQ Leader designation and Automations/Jira integrations. GitHub Copilot installs GPT-5.3-Codex as its first LTS model, ships Gemini 3.5 Flash GA, trims its Web Chat model menu ahead of June 1 billing, and open-sources the Eclipse plugin under MIT. Google's Antigravity 2.0 at I/O introduces a closed-source CLI replacing the open-source Gemini CLI — shutdown deadline June 18. Claude Code ships pinned background sessions, renames /simplify to /code-review (breaking), removes the legacy SDK (breaking), and demonstrates the Dreaming self-learning feature. Codex CLI v0.133.0 graduates Goals to GA. Devin adds Windows VM support and Auto-Triage; Replit Enterprise goes self-serve. Aider confirmed stalled at 9+ months.

Week of May 15–22, 2026
Two decisions framed this week more than any individual release. Cursor shipped Composer 2.5 built on an open-source checkpoint — Moonshot's Kimi K2.5 — and demonstrated that the benchmark gap between open and closed frontier models is now a pricing decision, not just an intelligence one. At Google I/O that same week, Google deprecated its open-source Gemini CLI and replaced it with a closed-source Go binary, drawing the opposite conclusion. Meanwhile Copilot promoted its first LTS model, Claude Code shipped a breaking rename and a same-day hotfix, and Codex CLI's Goals feature graduated from experimental to on-by-default.
Here's what shipped.
Cursor: Composer 2.5, Gartner MQ, and Automations
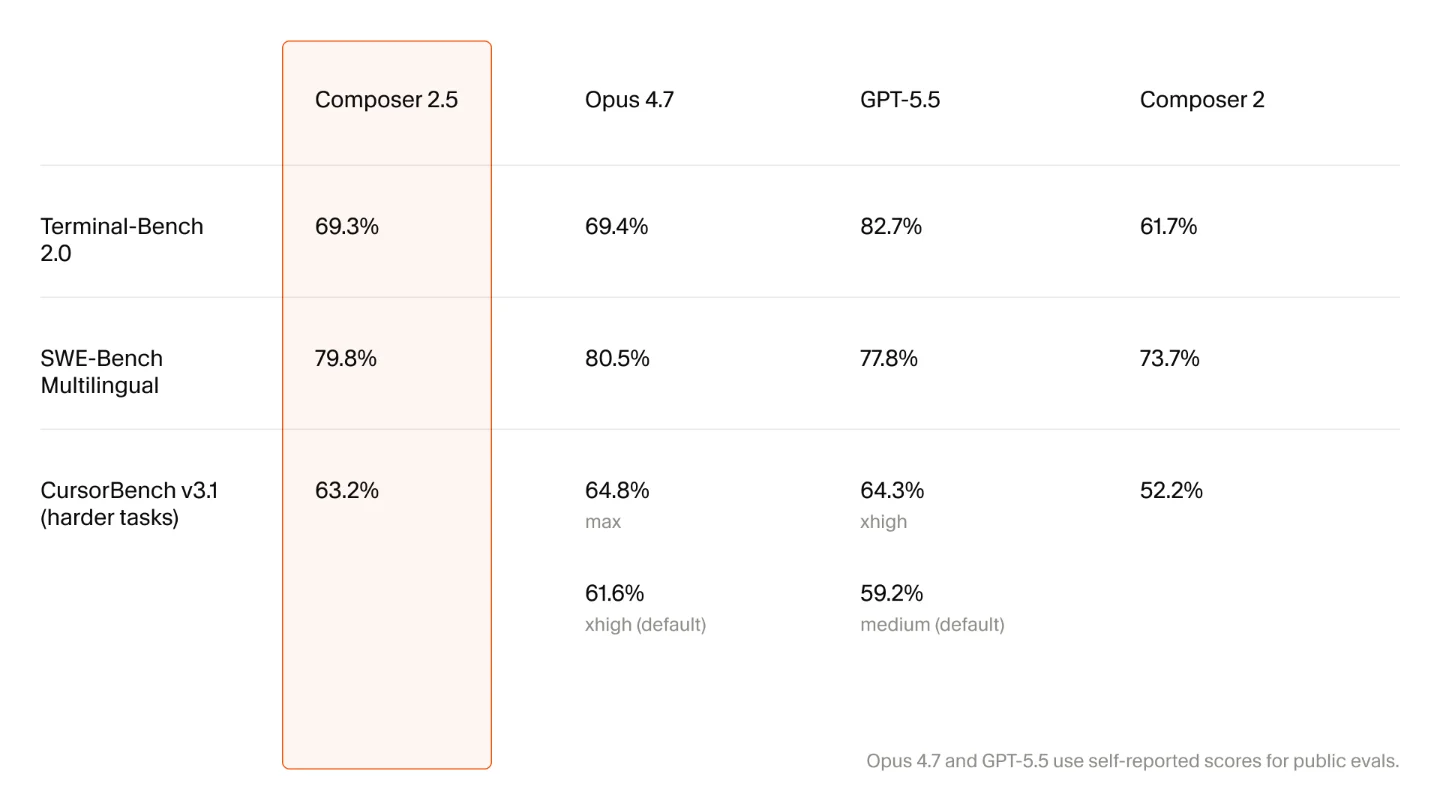
Composer 2.5 launched May 18, built on the same open-source Kimi K2.5 checkpoint as Composer 2. 1 The benchmarks improved substantially: Terminal-Bench 2.0 rose from 61.7% to 69.3% (+7.6 pp), CursorBench v3.1 from 52.2% to 63.2% (+11 pp). On SWE-Bench Multilingual it edges GPT-5.5 by roughly 2%, though both remain below Claude Opus 4.7. 2
Composer 2.5 vs. Composer 2, Opus 4.7, and GPT-5.5 across three benchmarks 1
Training used 25× the synthetic task volume of Composer 2, with targeted RL and textual feedback replacing earlier approaches. 1 Cursor describes the result plainly: "It's a substantial improvement in intelligence and behavior over Composer 2. It is better at sustained work on long-running tasks, follows complex instructions more reliably, and is more pleasant to collaborate with." 1
Pricing is the sharper story. Standard: $0.50/M input, $2.50/M output. Fast: $3.00/M input, $15.00/M output. 1 Opus 4.7 runs $5/$25 and GPT-5.5 runs $5/$30 per million tokens — meaning Composer 2.5 Standard is roughly 10× cheaper per output token than either. 3 For agent workloads measured in millions of output tokens, that gap matters more than 3 percentage points on a benchmark. The early caveat: The New Stack reports user feedback of the model occasionally losing task context mid-run, and it performs better on targeted edits than on UI work. 2 Cursor is also co-training the next generation model with SpaceXAI (formerly xAI) using 10× the current compute budget on the Colossus 2 cluster. 1
v3.5 (May 20) brought Automations into the Agents Window — previously manageable only at cursor.com/automations — with support for multi-repo automations and repo-less automations that monitor tools and signals without a codebase attachment. Five new Marketplace templates shipped: Slack digest, product analytics, FAQ, Stripe financial monitoring, and customer health. New automations get a 50% agent-run discount in their first week. 4
Jira integration went live May 19: assign a work item to Cursor in Jira or
@Cursor in a comment to trigger a cloud agent, which uses the ticket title, description, and comments to scope its work and posts a PR link when done. Requires Cursor admin permissions and Jira Commercial Cloud with Rovo. 4On May 22, Gartner named Cursor a Leader in the 2026 Magic Quadrant for Enterprise AI Coding Agents — farthest on the Completeness of Vision axis — and Cursor cited that over 70% of the Fortune 500 now use its platform. 5
Loading link preview…
A May 21 engineering post by Josh Ma revealed that over 40% of Cursor's own PRs now come from cloud agents, with Temporal handling 50M+ daily actions across 7M+ independent workflows. 6 Early reliability sat at "one 9" before the Temporal migration; it now exceeds two 9s. Ma's framing is useful for teams architecting their own agent systems: "the single biggest factor in cloud agent output quality is ensuring it has a full development environment, like a developer has." 6
GitHub Copilot: LTS model, Gemini Flash, and a streamlined model menu
GPT-5.3-Codex became the base model for all Copilot Business and Enterprise organizations on May 17, replacing GPT-4.1. 7 It is the first Copilot model designated as LTS — guaranteed available until 2027-02-04, which gives teams with policy-review cycles a stable target. It carries a 1× premium request multiplier. GPT-4.1 remains force-enabled at 0× cost until June 1, when usage-based billing activates and GPT-4.1 is retired. 7
Gemini 3.5 Flash reached general availability across Copilot on May 19, covering VS Code, Visual Studio, JetBrains, Xcode, and Eclipse. 8 The multiplier is 14× (provisional) — expensive relative to the GPT-5.3-Codex baseline, so teams should treat it as an opt-in for latency-sensitive tasks rather than a replacement for the default.
The same day (May 20), GitHub trimmed the Web Chat model list: all Gemini models, GPT-5.2 Codex, and GPT-5.4 nano were removed, leaving only OpenAI and Claude options. 9 The rationale given was consistency — fewer models, more predictable quality across sessions. The timing is deliberate: a simpler, tested model menu before June 1 billing makes cost projections easier for both GitHub and its customers.
VS Code Auto model selection also upgraded on May 20 to task-based routing: the system now uses real-time utilization and model health signals to pick the model per request, with a 10% credit discount for paid users. It only routes within the 0×–1× multiplier band. 10
For the cloud agent, May 18 added two fast, low-cost model options: Claude Haiku 4.5 at 0.33× and GPT-5.4-mini at 0.33×. 11 These are for simple, high-volume tasks — ticket triage, stub generation, test scaffolding — where paying 1× for Codex is overkill.
GitHub Copilot for Eclipse went open-source on May 21 under the MIT license at
github.com/microsoft/copilot-for-eclipse. 12 The scope is substantial: code completion, Next Edit Suggestions, Chat, Agent mode, Skills and prompt files, BYOK, custom agents, isolated sub-agents, plan agent, and MCP integration. GitHub stated: "Eclipse has thrived for decades thanks to its open ecosystem, and we believe AI tooling should be developed in that same spirit." 12Copilot CLI shipped six releases this week (v1.0.49 through v1.0.52-2). 13 Highlights worth testing:
/rubber-duck(v1.0.49, May 18): runs an independent critical review of your current session — useful for catching blind spots before you commit/security-review(v1.0.51, May 20): experimental; runs a security-focused pass over current changes- Context window tier selection (v1.0.52-2, May 22): choose between ~200K and 1M token context windows end-to-end
- Customizable status line showing model, context window usage, and git branch
The context window tier addition is the structurally interesting one — it implies the 1M context path is now stable enough for user-facing control rather than being an internal toggle.
A reminder heading into June: usage-based billing (AI Credits, 1 credit = $0.01) activates on June 1. Code completions and Next Edit Suggestions remain unmetered. 3 If your team hasn't pulled the April usage preview report GitHub published last week, do that before the billing flip.
Google Antigravity 2.0: new platform, new pricing, Gemini CLI shutdown
Google used I/O 2026 (May 19–20) to reframe its developer tools under a single brand: Antigravity 2.0, described as "our agent-first development platform for developers to take an idea and turn it into a production-ready app." 14
Loading link preview…
The platform has four new components:
- Antigravity desktop app: multi-agent orchestration, parallel execution, scheduled tasks, voice commands
- Antigravity CLI: a new Go binary that replaces Gemini CLI
- Antigravity SDK: a Python wrapper around the Go binary
- Managed Agents API: a single API call that spins up an agent with an isolated Linux environment 15
Pricing update: a new $100/month AI Ultra tier provides 5× the Pro usage limits, making it more accessible than the existing $250 Ultra (which dropped to $200 and now offers 20× Pro limits). 15
⚠️ Breaking for Gemini CLI users: Google announced that Gemini CLI — the Apache 2.0 TypeScript tool currently used by Google AI Pro/Ultra and free tier users — and the Gemini Code Assist IDE extension will stop serving those users on June 18, 2026. 16 Enterprise paid customers are not affected. The replacement, Antigravity CLI, is a closed-source Go binary.
This reversal — open-source TypeScript to closed-source Go — has drawn pointed criticism. Independent analyst Simon Willison flagged a security concern specific to the Gemini Spark integration that will route sensitive data through the new binary: "Given how many people are going to be piping very sensitive data through Gemini Spark in the near future I hope they've made this bullet-proof." 17 He also noted the opacity of switching from an auditable Apache-licensed codebase to an unauditable Go binary as a meaningful shift in trust posture.
For teams currently on Gemini CLI: the migration deadline is June 18, less than four weeks out.
Claude Code: pinned sessions, /code-review, and a breaking SDK migration
This was a technically dense week for Claude Code: six releases (v2.1.143 → v2.1.148), two capability additions, and one breaking change. 18
Pinned background sessions (v2.1.147, May 21):
Ctrl+T in claude agents now pins a session. Pinned sessions stay alive when idle, restart in-place when Claude Code updates, and are only shed under memory pressure after non-pinned sessions are cleared first. 18 For teams running long-lived agent contexts — a persistent code reviewer, a monitoring session — this removes the current frustration of sessions dying on update./simplify renamed to /code-review (v2.1.146, May 21): the command now supports effort levels (/code-review high) and a --comment flag that posts findings as inline comments on a GitHub PR. 18 The original cleanup-and-fix behavior has been removed — if your team has workflows or scripts calling /simplify, those break.v2.1.148 (May 22) was a same-day hotfix for a Bash exit code 127 regression introduced in v2.1.147. 18 Stay on v2.1.148 or later.
⚠️ Breaking: legacy SDK entry points removed. The
@anthropic-ai/claude-code legacy SDK entrypoints have been removed; projects must migrate to @anthropic-ai/claude-agent-sdk@0.2. 19 Any CI pipelines or integrations importing from the old package will fail until updated.Loading link preview…
On the product direction side: at the London Code with Claude event on May 19, Anthropic demonstrated Dreaming — an agent self-note system where Claude Code writes structured notes about a codebase after completing tasks, and subsequent agent sessions read those notes to ramp up faster and avoid repeated mistakes. 20 The mechanism is straightforward (notes as persistent context), but the compounding effect over a codebase that sees hundreds of agent sessions a week is worth watching.
The repository is at 126K GitHub stars, up roughly 1K this week. 21
Codex CLI v0.133.0: Goals are on by default
OpenAI shipped v0.133.0 on May 21. The version number jumped from 0.131.0-alpha.19, bypassing the expected 0.131.0 — 0.133.0 reflects the accumulated weight of changes. 22
Goals go GA: the feature is now enabled by default, backed by a dedicated goal database that persists progress across active turns. This moves Codex from session-local context to something closer to a persistent task-tracking layer. 22
codex remote-control shifts from a background daemon to a foreground command: it waits until the agent is ready, reports machine state, then exits — while still supporting explicit start/stop for daemon-style usage. This makes the remote-control workflow more legible, though a known quirk: only sessions with an explicit name field appear in the listing. Sessions stuck at the default "preview" name won't show up until renamed with /rename and the server is restarted. 22Other additions: permission profile list API, inheritance, runtime refresh, and Windows sandbox integration; plugin marketplace now separates list and request tools with marketplace-aware output; extension lifecycle hooks added for subagent start/stop, tool execution, and turn metadata. 22
The repository is at 84.7K stars. 22
Brief notes
Devin — Windows PC support (Beta, May 21): Cognition added native Windows VM support, targeting .NET Framework → .NET Core migrations, Windows Forms/VB/ASP legacy modernization, Windows UI test automation via Computer Use, and SQL Server / Windows Services workflows. 23 Currently limited to Enterprise Cloud and Dedicated Deployment customers. The Windows install base — over 1.4 billion devices, by Cognition's count 23 — means this expands Devin's addressable workflow surface substantially, even if most teams won't hit it this week.
Devin — Auto-Triage (May 18): Devin Automations can now monitor Slack, Linear, GitHub, Datadog, Sentry, and custom webhooks for alerts and bug reports, investigate automatically, and open PRs when the fix is clear. 24 Modal's Hari Subbaraj put it directly: "Devin works on its own, and we can wake up to really good investigation without prompting it." 24 New users who set up their first automation get $200 in credits.
Replit Enterprise self-serve (May 21): Enterprise plans are now purchasable directly on the Replit site — SSO (SAML/Okta/Azure AD/Google Workspace/OneLogin), SCIM, RBAC, audit logs, and SOC 2 included, no contract negotiation required. 25 Billing is annual credit pools rather than per-seat, with default unlimited seats. Teams above the Pro 15-seat cap should find this removes the main friction to upgrading.
Grok Build: no changes this week. Still early beta, SuperGrok Heavy subscribers only (~$300/month), SWE-bench Verified at 70.8% (below Claude Code's 87%), up to 8 parallel sub-agents. 26 The
/skillify command — which converts any session into a reusable skill — remains a differentiated feature not yet matched by the other CLI agents.Windsurf v2.3.9 (May 17): bug fixes only — swe-check model availability, terminal handling performance, conversation sharing, and WSL path resolution for Devin local agent. 27 No new models, no features. Windsurf's free-tier model removal (reported in community forums around May 13) still has no official changelog entry.
Aider: confirmed stalled at v0.86.0 (August 9, 2025) — over nine months without a release and no public statement from maintainer Paul Gauthier. 28 The community still cites it for production reliability, but the gap between its last release and Claude Code's six-versions-a-week cadence is now too wide to close without a deliberate restart.
Zerostack v1.0.0 (May 17): a Unix-philosophy coding agent written entirely in Rust, published on crates.io, topped Hacker News at 572 points and 307 comments. 29 No enterprise backing, no benchmark claims — the pitch is clean architecture and the ability to fork from source.
Tabnine and Continue.dev had no new releases this week.
Cover: Composer 2.5 benchmark table from Cursor: Introducing Composer 2.5
References
- 1Cursor: Introducing Composer 2.5
- 2The New Stack: Cursor bets on cheaper coding with Composer 2.5 and Kimi K2.5
- 3GitHub Docs: Models and pricing for GitHub Copilot
- 4Cursor: Changelog
- 5Cursor: Cursor named a Leader in the 2026 Gartner® Magic Quadrant™
- 6Cursor: What we've learned building cloud agents
- 7GitHub: GPT-5.3-Codex is now the base model
- 8GitHub: Gemini 3.5 Flash is GA for Copilot
- 9GitHub: Updates to available models in Copilot on web
- 10GitHub: Auto model selection now routes based on your task in VS Code
- 11GitHub: Copilot cloud agent fast models
- 12GitHub: GitHub Copilot for Eclipse is open source
- 13GitHub: Copilot CLI Releases
- 14Google: I/O 2026 developer highlights
- 15TechCrunch: Google launches Antigravity 2.0
- 16Google: Transitioning Gemini CLI to Antigravity CLI
- 17Simon Willison: Google I/O, Gemini Spark, Antigravity
- 18Anthropic / GitHub: Releases · anthropics/claude-code
- 19ClaudeFa.st: Claude Code Changelog (SDK migration)
- 20MIT Technology Review: Anthropic's Code with Claude showed off coding's future
- 21Anthropic: GitHub - anthropics/claude-code
- 22OpenAI / GitHub: Releases · openai/codex (v0.133.0)
- 23Cognition Labs: Devin is Getting a Windows PC
- 24Cognition Labs: Introducing Auto-Triage
- 25Replit: Replit Enterprise, Now Self-Serve
- 26xAI: Grok Build Beta
- 27Codeium/Windsurf: Editor Changelog
- 28GitHub: Releases · Aider-AI/aider
- 29Hacker News: Zerostack
Add more perspectives or context around this Drop.